
ช่วงนี้ลงเรียน Bootcamp ของ Datarockie อยู่แหละครับ รุ่นที่ลงก็เป็นรุ่นที่ 12 แล้ว แอดทอยสอนเข้าใจง่าย แนะนำเลย ก็เลยมาเขียนเป็นบทความสรุปความรู้ แล้วแชร์ให้เพื่อนๆ อ่านด้วยดีกว่า (ที่จริงเป็นการบ้านที่แอดทอย ให้มาเขียนสรุปด้วยแหละ 555) มาเริ่มกันเลย!
Statistic ก็คือการเก็บข้อมูล และก็นำข้อมูลนั้นๆ มาวิเคราะห์ต่อ แต่ทีนี้ในความเป็นจริงเราอาจจะไม่สามารถเก็บข้อมูลได้ทั้ง 100% เพื่อนำมาประมวลผล (ลองนึกภาพการเก็บข้อมูลประชากรทั้งประเทศ) ดังนั้นเราจึงจำเป็นต้องเก็บจากกลุ่มตัวอย่างเพื่อมาวิเคราะห์แทน
จำนวนประชากรทั้งหมด = Population
จำนวนกลุ่มตัวอย่าง = Sample จุดที่น่าสนใจจึงมาอยู่ที่ Sample แล้วละครับ ทำอย่างไรจึงจะได้ Sample ที่มีคุณภาพ แสดงผลได้ใกล้เคียง Population ทั้งหมดได้ ซึ่งวิธีของการกำหนด Sample มีดังนี้
1. Probability Sampling
2. Non-Probability Samplingเรามาดูกันทีละตัว เริ่มจาก Probability Sampling ก่อน ซึ่งจะประกอบด้วย 4 วิธีการย่อยดังนี้
Probability Sampling
1. Simple Random Sampling
2. Systematic Random Sampling
3. Stratified Random Sampling
4. Cluster Random SamplingSimple Random Sampling
วิธีการนี้ก็จะเป็นการสุ่มกลุ่มตัวอย่างจาก Population ทั้งหมดที่มีอยู่เลย แต่วิธีการนี้ เราจะต้องมีรายชื่อของ Population ทั้งหมดอยู่ในมือก่อนนะ แล้วค่อยสุ่มออกมาจำนวนหนึ่ง การสุ่มจะเป็นการสุ่มแบบไม่มีหลักการอะไรเลย สุ่มแบบจริงๆ จังๆ ถือว่าเป็นวิธีการเลือก sampling ที่ง่าย ไม่ซับซ้อน และเป็นกลางดี
Systematic Random Sampling
วิธีการนี้ก็เป็นการสุ่มเหมือนกัน แต่จะเป็นการสุ่มที่เอาหลักการบางอย่างเข้ามาจับด้วย เช่น เราจะไปเก็บข้อมูลตามบ้านต่างๆ เราอาจจะตั้ง system ว่า เราจะเข้าไปเก็บข้อมูลบ้าน 1 หลัง แล้ว skip ไป 4 หลัง และถ้าเจอทางแยกจะต้องเลี้ยวซ้ายตลอด

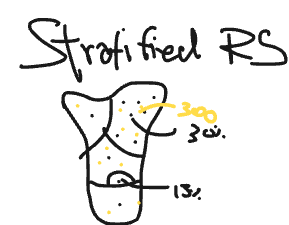
Stratified Random Sampling
วิธีการนี้จะเป็นการแบ่งกลุ่มตัวอย่างเป็นสัดส่วนให้สอดคล้องกับ Population เช่นแต่ละภาคในประเทศไทยมีสัดส่วนประชากรต่างกัน วิธีการนี้จะเป็นการบอกว่าในแต่ละภาคจะต้องมี sampling เท่าไหร่ เพื่อที่จะให้แสดงถึง Population ให้ได้มากที่สุด
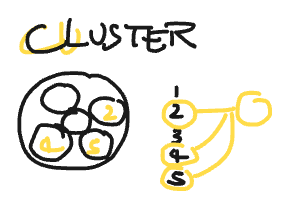
Cluster Random Sampling
วิธีการนี้คือแบ่ง Population เป็นกลุ่มๆ (Cluster) แล้วก็สุ่มมาว่าเราจะไปเก็บข้อมูลที่กลุ่มไหน
เรามาดูฝั่ง Non-Probability Sampling กันบ้าง ซึ่งตรงนี้ก็จะมีอยู่ 2 วิธี
Non-Probability Sampling
1. Convenience Sampling
2. SnowballConvenience Sampling
วิธีการนี้คือวิธีการง่ายๆ แต่กลุ่มตัวอย่างที่ได้มาจะมีโอกาสที่ไม่มีคุณภาพ เพราะมันเป็นวิธีที่ง่ายนั้นแหละ เช่นการเอาแบบสำรวจไปเก็บข้อมูลโดยการโพสลงในกลุ่ม online ต่างๆ เช่น facebook กลุ่ม line ซึ่งวิธีการเหล่านี้จะไม่เหมาะกับการนำมาใช้จริง
Snowball
วิธีการนี้จะใช้กับการเก็บข้อมูลที่ค่อนข้างยากและเฉพาะทาง คือพอเริ่มเก็บได้กับคนแรกแล้ว เราก็จะถามคนแรกว่ามีใครแนะนำบ้าง เราก็ตามๆ ไปเก็บต้อง ซึ่งข้อมูลที่ได้จะไม่มีการกระจายตัวที่ดี
ต่อมาเมื่อเราได้ข้อมูลมาแล้วจากการทำ sampling อย่างที่เราต้องการ ก็ถึงเวลามาดูว่าข้อมูลที่เราได้มานั้นมี insight อย่างไร มีคุณภาพขนาดไหน ซึ่งข้อมูลที่มีการกระจายตัวที่ดีควรจะอยู่ในลักษณะของ Normal distribution curve
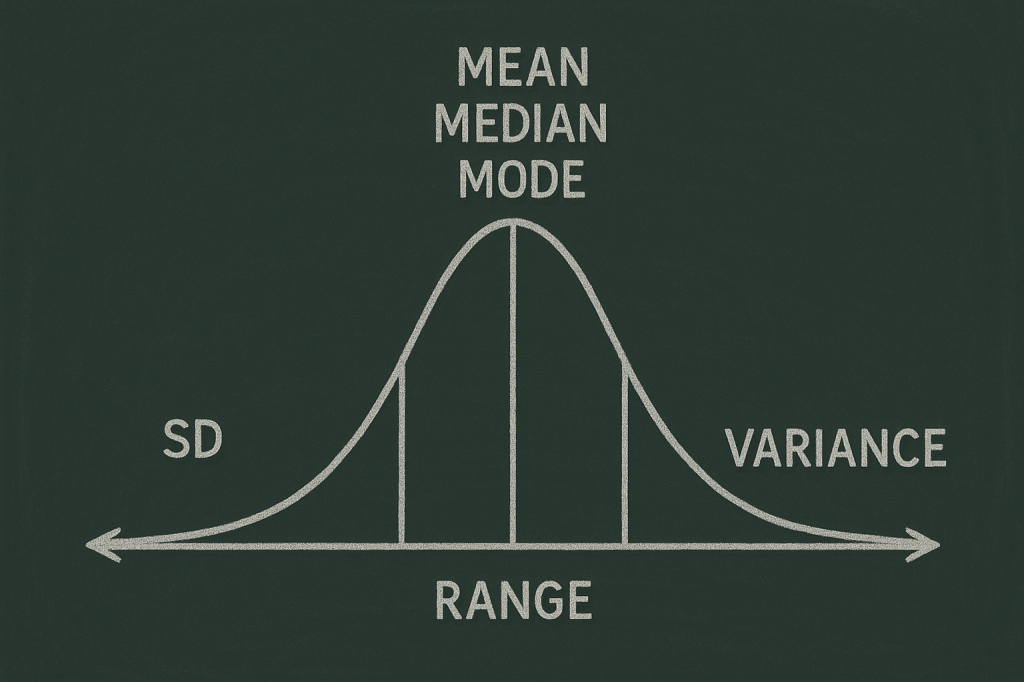
เรามาดูกันทีละค่า
Mean ก็คือค่าเฉลี่ยของ data ทั้งหมด
Median ก็คือค่าที่อยู่ตรงกลาง
Mode ก็คือค่าที่มีมากที่สุด
ซึ่งถ้าข้อมูลที่เราเก็บมา บางครั้งก็อาจจะไม่อยู่ในลักษณะนี้ เช่นข้อมูลรายได้ของประชากรทั้งประเทศ Mean อาจจะสูงกว่าความเป็นจริง เพราะเพียงแค่มีคนกลุ่มเล็กๆ ที่มีรายได้เยอะดึง mean ไว้อยู่

เราจึงต้องมาสนใจการกระจายตัวของข้อมูลอีกว่าข้อมูลมีการกระจายตัวเป็นอย่างไรจากค่า SD และ Variance ค่าเหล่านี้จะมีสูตรอยู่ 2 แบบ คือ ที่หาจาก Population ทั้งหมด กับ หาจาก Sampling มันต่างกันที่ตัวหาร คือถ้า Population จะ หาร N แต่ sample จะหาร n-1 คือตัวสูตรจะเหมือนกัน แต่ถ้าเป็น Population จะใช้ อักษรโรมันแทน ตามนี้


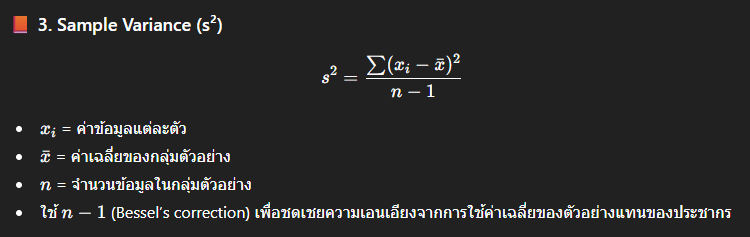

เห็นสูตรแล้วน่ากลัวเลย แต่จริงๆ แล้วมันเข้าใจง่ายนะมาดูแบบนี้
ยกตัวอย่างจากชุดข้อมูลตัวอย่างแล้วกัน
อย่างแรกเราต้องรู้ก่อนว่า mean หรือ x bar ของชุดข้อมูลของเรานั้นอยู่ที่เท่าไหร่ ตัวอย่างชุดข้อมูลเป็นคะแนนสอบ จะเห็นว่าคะแนนสอบเฉลี่ยจะอยู่ที่ 66.75 การที่เราเอา x – x bar ก็จะทำให้เห็นได้ว่า แต่ละคะแนนนั้นมีความห่างจากค่าเฉลี่ยเท่าไหร่ และนี่แหละ มันเป็นตัวที่จะบอกเราได้ว่ามีการเบี่ยงออกเป็นอย่างไร

โดยที่ในช่อง x – x bar ถ้าเราเอามา sum รวมกันมันจะเป็น 0 เพราะมีจะต้องมีทั้งมากกว่าและน้อยกว่าค่าเฉลี่ยตรงกลาง เพื่อที่จะให้มาคำนวนหาค่า Variance ได้นั้น ก็เลยจะต้องเอามายกกำลังสองก่อนเอามารวมกันไง! ทำต่อมาก็จะได้แบบนี้
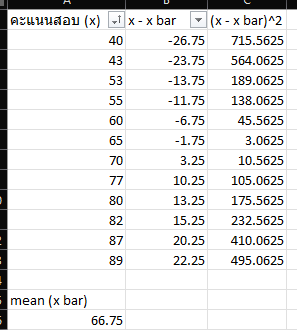
แค่นี้เราก็จะสามารถเอามารวมกันเพื่อหาค่า Variance ที่จะดูว่ามันมีความแปรปรวนขนาดไหน ก็จับมา รวมกัน แล้วหารด้วย n-1 ก็จะได้มาเป็น 256.02.. ซึ่งมันเป็นค่าที่มองยากนะว่ามันเบี่ยงออกมาเท่าไหร่ มันไม่มีหน่วย เราจึงต้องทำให้มันเข้าใจง่ายโดยทำให้กับมาเป็นหน่วยที่เข้าใจ โดยการที่ก่อนหน้าที่เรา ยกกำลังสอง เราก็เลยจับมันถอดรูท ซะเลย
พอถอดรูทแล้ว มันก็คือค่า SD นั้นเอง บอกเราได้ว่ามันเบี่ยงเบนออกมา 1 ช่อง SD คือ ค่าเท่าไหร่ ในที่นี้ 1 SD ก็ประมาณ 16 คะแนน
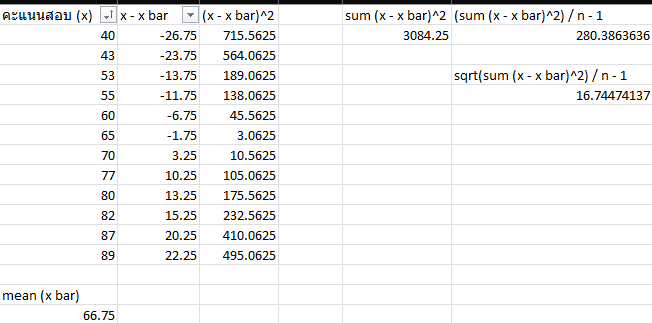
พอเราเข้าใจเรื่องพื้นฐานพวกนี้แล้ว ชีวิตเราก็จะง่ายขึ้น ใช้สูตรได้อย่างเข้าใจ เท่ากันเป๊ะ!

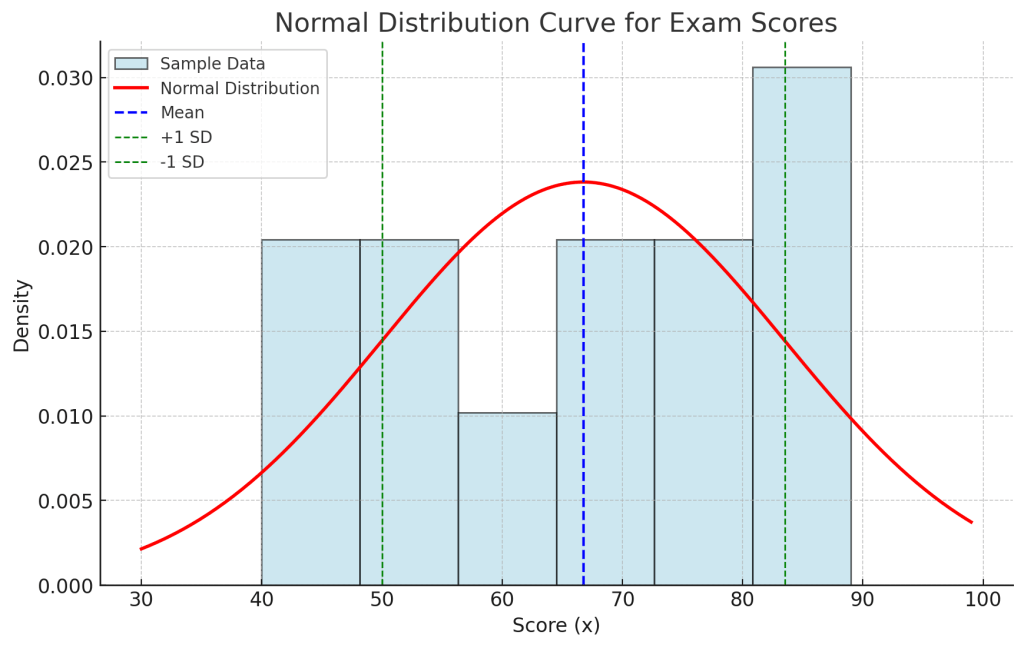
เวลาเอามา plot เป็น graph ก็จะได้รูปลักษณะนี้
1 SD มันก็คือค่าเบี่ยงออกจากตรงกลาง 16.74 ตามรูปนี่เอง
Range ก็เข้าใจง่ายๆ คือ ค่า max – min ของข้อมูลเพื่อดูว่ามีช่วงเท่าไหร่ ในที่นี้ก็ 89 – 40 ก็จะมี range อยู่ที่ 49
สุดท้ายก็จะสามารถนำไปบอก position ได้อีกในลักษณะของ Quartile, Percentile ก็จะเทียบตามข้อมูล min, max, median ได้เลย ว่าข้อมูลนั้นๆ จะอยู่ที่ Quartile ที่เท่าไหร่ (1 Quartile ก็คือ quarter หรือ 25% นั้นแหละ)
